Visual understanding
The Pinterest visual embedding system is trained with a large multimodal pre-training contrastive task, and fine-tuned with dozens of visual-specific and retrieval-specific datasets, enabling state-of-the-art visual search.
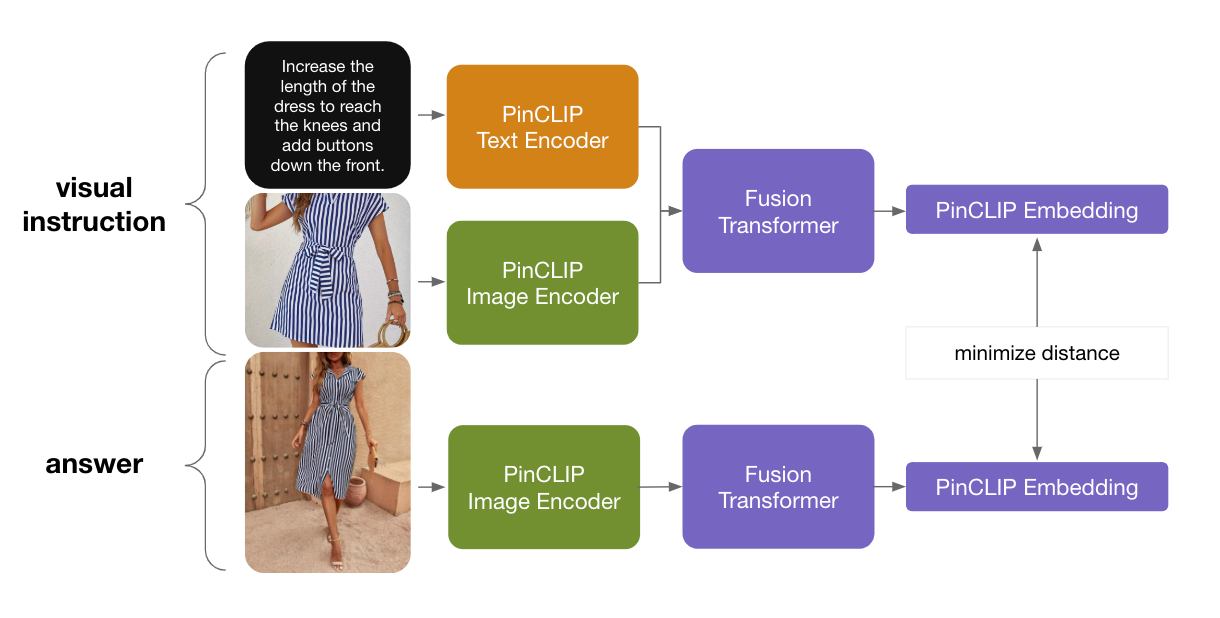
The Pinterest visual embedding system is at the center of the visual understanding that underpins Pinterest. The current iteration of this technology is trained with a large multimodal pre-training contrastive task to align representations from the Pinterest graph-sampled image-text pairs. A series of fine-tuning stems with dozens of visual-specific and retrieval-specific datasets, result in a state-of-the-art representation system for retrieval.
These embeddings are then optimized for compatibility with multimodal query understanding, diffusion model conditioning, LLM image projection, and more, and are deployed throughout the Pinterest product across every major ML surface.
